# 双手机器人灵巧操作研究
双手机器人灵巧操作因其高自由度协调、多模态感知融合以及复杂技能组合等挑战,已成为机器人学领域的重要研究方向。传统的单手机器人操作技术虽然能够利用人类演示数据指导强化学习方法,但在涉及多个子技能的双手协调任务中往往难以泛化。特别是在动态场景下,当被操作物体状态发生变化时,被动手需要根据实时三维姿态变化做出响应,而现有方法缺乏对物体姿态和尺寸的显式感知,导致在动态状态下的手部运动不协调。此外,成功的操作任务需要时间对齐的子技能组合,如被动手必须在主动手开始旋转之前建立稳定的抓取,但现有方法缺乏协调这些相互依赖子过程的机制。
为解决上述问题,浙江大学控制科学与工程学院工业控制研究所叶琦团队的孙正男等研究人员开展了《VTAO-BiManip:基于掩码视觉-触觉-动作预训练与物体理解的双手机器人灵巧操作研究》,旨在通过多模态预训练和课程强化学习实现类人双手机器人操作。该研究成果已在机器人学领域知名会议IROS发表。
*图1:左图展示了瓶盖旋转数据集示例;中图显示了使用Shadow Hand的瓶盖任务仿真结果;右图展示了使用Leap Hand的真实世界部署
# 一、研究方案:
研究团队设计并构建了一个VTAO(视觉-触觉-动作-物体)数据采集系统,用于捕获人类双手操作演示数据。该系统包括:1)Hololens2用于视觉数据采集;2)双手触觉和运动采集手套;3)青瞳视觉动捕系统用于精确捕获手部运动和6自由度物体姿态;4)个人计算机负责数据采集
和对齐。通过该系统,收集了216个人类双手操作轨迹,涉及26个不同瓶子,每个轨迹持续6-17秒,总计61,684帧时间对齐的多模态数据。
*图2:用于人类双手操作的VTAO数据采集系统*
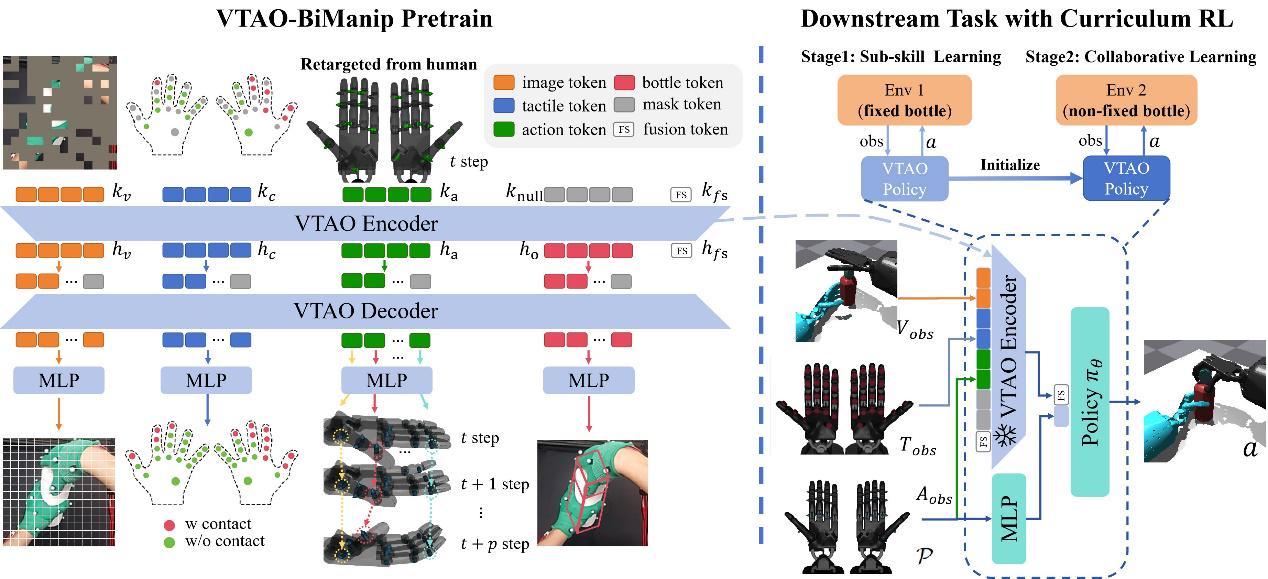
基于MAE(掩码自编码器)架构,研究团队提出了VTAO-BiManip预训练框架,该框架采用编码器-解码器结构:编码器处理视觉、触觉和当前动作输入,通过注意力机制将不同模态信息投影到潜在令牌中;解码器重建原始感知模态,预测后续动作,并估计物体状态。这种联合重建机制在预训练过程中实现了跨模态特征融合,使模型能够从部分感知观察中恢复完整的环境交互。
*图3:VTAO-BiManip预训练框架及其下游双手操作与子技能协作课程强化学习概览*
为解决多技能学习挑战,研究团队采用PPO强化学习策略,并引入了两阶段课程强化学习框架:第一阶段将瓶子固定在桌面上,鼓励左手学习抓取瓶子,右手学习拧开瓶盖;第二阶段释放瓶子,强制双手协作操作技能学习。
方案创新及优势:
1、引入了动作预测和物体理解作为补充模态,实现了跨模态特征融合
2、设计了VTAO数据采集系统,捕获了人类双手操作的多模态演示数据
3、提出了两阶段课程强化学习框架,有效解决了双手子技能学习挑战
4、在仿真和真实环境中验证了方法的有效性,成功率超过现有方法20%以上
# 二、实验验证:
该实验在Isaac Gym仿真环境中部署了双手瓶盖旋转任务,选择了15个来自ShapeNet的不同瓶子,其中10个用于训练,5个用于测试。实验使用Intel Xeon Gold 6326和NVIDIA 3090系统,预训练阶段使用AdamW优化器,学习率为2e-5,掩码比例设置为视觉0.75、触觉0.5、动作0.5。强化学习阶段采用两阶段课程学习,第一阶段训练1000次迭代,第二阶段训练3500次迭代,总计约62小时。
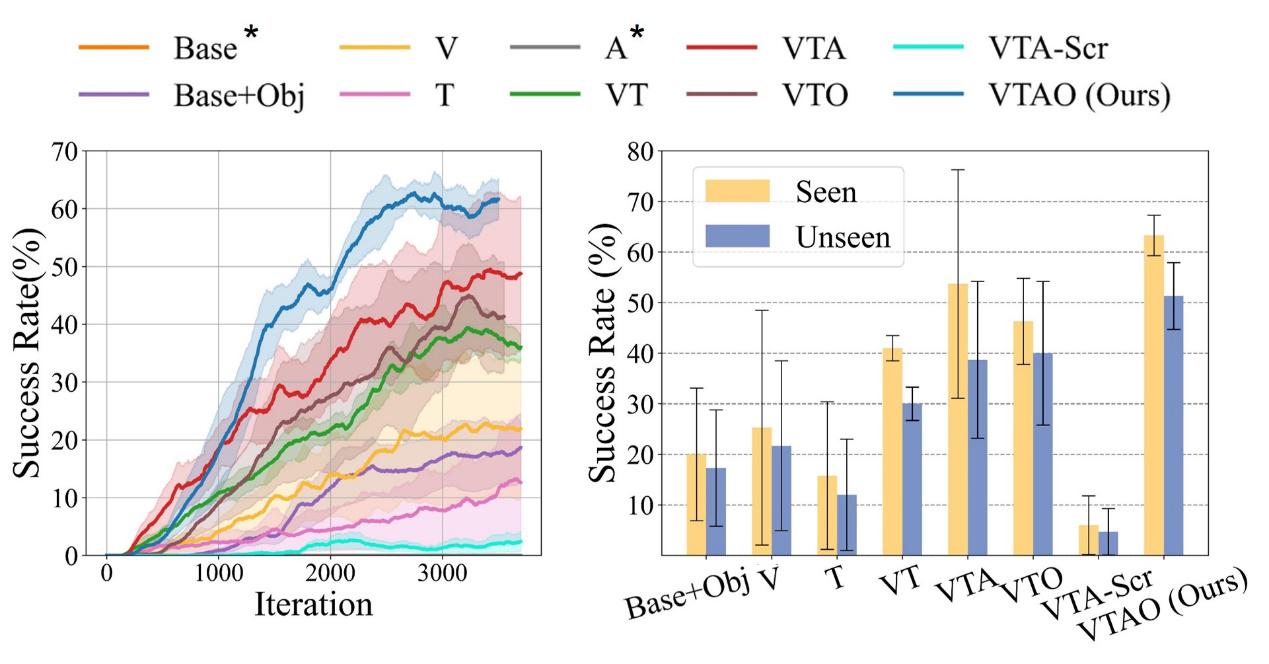
*图4:不同预训练方法在仿真中的定性结果。左图:训练过程;右图:评估结果*
通过对比不同模态配置的基线方法,实验结果表明:1)多模态联合预训练方法VTA显著优于单模态预训练方法V、T、A以及无预训练的多模态方法VTA-Scr;2)从VT到VTA(加入动作模态预测)和VTO(加入物体理解)的性能提升表明,动作预测和物体理解都能显著增强视觉-触觉融合;3)VTAO通过结合两种模态实现了最高成功率,表明动作预测和物体理解任务具有互补效益。
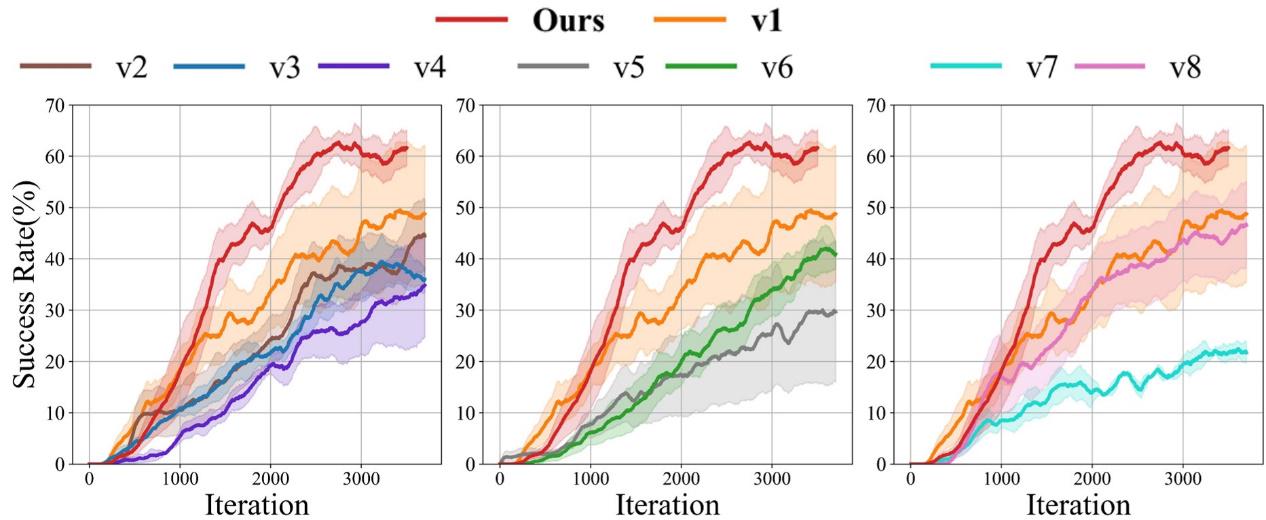
*图5:消融研究的训练过程。左图:双手操作验证;中图:动作预测范围消融;右图:动作令牌数量消融*
消融研究进一步验证了关键设计选择:1)使用双手数据相比仅使用右手数据,无论移除哪种模态都能获得更高的成功率;2)动作预测机制显著提升了下游任务性能;3)物体理解模块对于实现基于目标物体状态的动态操作策略调整至关重要。
# 三、实验成果:
本研究表明,VTAO-BiManip框架通过多模态预训练和课程强化学习的结合,成功实现了双手灵巧操作。该方法在仿真环境中达到了63%的成功率(已见物体)和51%的成功率(未见物体),相比现有方法提升了超过20%的性能。研究团队还在真实环境中验证了方法的有效性,如图6所示。
*图6:我们的操作平台*
# 四、参考文献:
1 Liu Y, et al. M2VTP: Masked Multi-modal Visual-Tactile Pre-training for Robotic Manipulation. ICRA 2024.
2 Chen Y, et al. Towards human-level bimanual dexterous manipulation with reinforcement learning. NeurIPS 2022.
3 Qin Y, et al. DexMV: Imitation learning for dexterous manipulation from human videos. ECCV 2022.
4 Rajeswaran A, et al. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations. RSS 2018.
5 He K, et al. Masked autoencoders are scalable vision learners. CVPR 2022.
6 Chen Y, et al. Visuo-tactile transformers for manipulation. CoRL 2022.
7 Li H, et al. See, Hear, and Feel: Smart Sensory Fusion for Robotic Manipulation. CoRL 2023.
8 Zhao T Z, et al. Learning fine-grained bimanual manipulation with low-cost hardware. arXiv 2023.
9 Kataoka S, et al. Bi-manual manipulation and attachment via sim-to-real reinforcement learning. arXiv 2022.
10 Chen Y, et al. Sequential dexterity: Chaining dexterous policies for long-horizon manipulation. arXiv 2023.
11 Nair S, et al. R3M: A universal visual representation for robot manipulation. arXiv 2022.
12 Brohan A, et al. RT-1: Robotics transformer for real-world control at scale. arXiv 2022.
13 Xiao T, et al. Masked visual pre-training for motor control. arXiv 2022.
14 Yuan W, et al. GelSight: High-resolution robot tactile sensors for estimating geometry and force. Sensors 2017.
15 Makoviychuk V, et al. Isaac gym: High performance gpu-based physics simulation for robot learning. arXiv 2021.
# 五、原文链接:
https://arxiv.org/abs/2501.03606
https://suzend.github.io/VTAO-Bimanip/